DR Solution Based on Cross-Region Deployment in a Single Cluster
How disaster recovery works in GreptimeDB
GreptimeDB is well-suited for cross-region disaster recovery. You may have varying regional characteristics and business needs, and GreptimeDB offers tailored solutions to meet these diverse requirements.
GreptimeDB resource management involves the concept of Availability Zones (AZs). An AZ is a logical unit of disaster recovery. It can be a Data Center (DC), a compartment of a DC. This depends on your specific DC conditions and deployment design.
In the cross region disaster recovery solutions, a GreptimeDB region is a city. When two DC are in the same region and one DC becomes unavailable, the other DC can take over the services of the unavailable DC. This is a localization strategy.
Before understanding the details of each DR solution, it is necessary to first understand the following knowledge:
- The DR solution for the remote wal component is also very important. Essentially, it forms the foundation of the entire DR solution. Therefore, for each DR solution of GreptimeDB, we will let the remote wal component in the diagram. Currently, GreptimeDB's default remote wal component is implemented based on Kafka, and other implementations will be provided in the future; however, there won't be significant differences in deployment.
- The table of GreptimeDB: Each table can be divided into multiple partitions according to a certain range, and each partition may be distributed on different datanodes. When writing or querying, the specified node will be called according to the corresponding rules. A table's partitions might look like this:
Table name: T1
Table partition count: 4
T1-1
T1-2
T1-3
T1-4
Table name: T2
Table partition count: 3
T2-1
T2-2
T2-3
Metadata across 2 regions, data in the same region
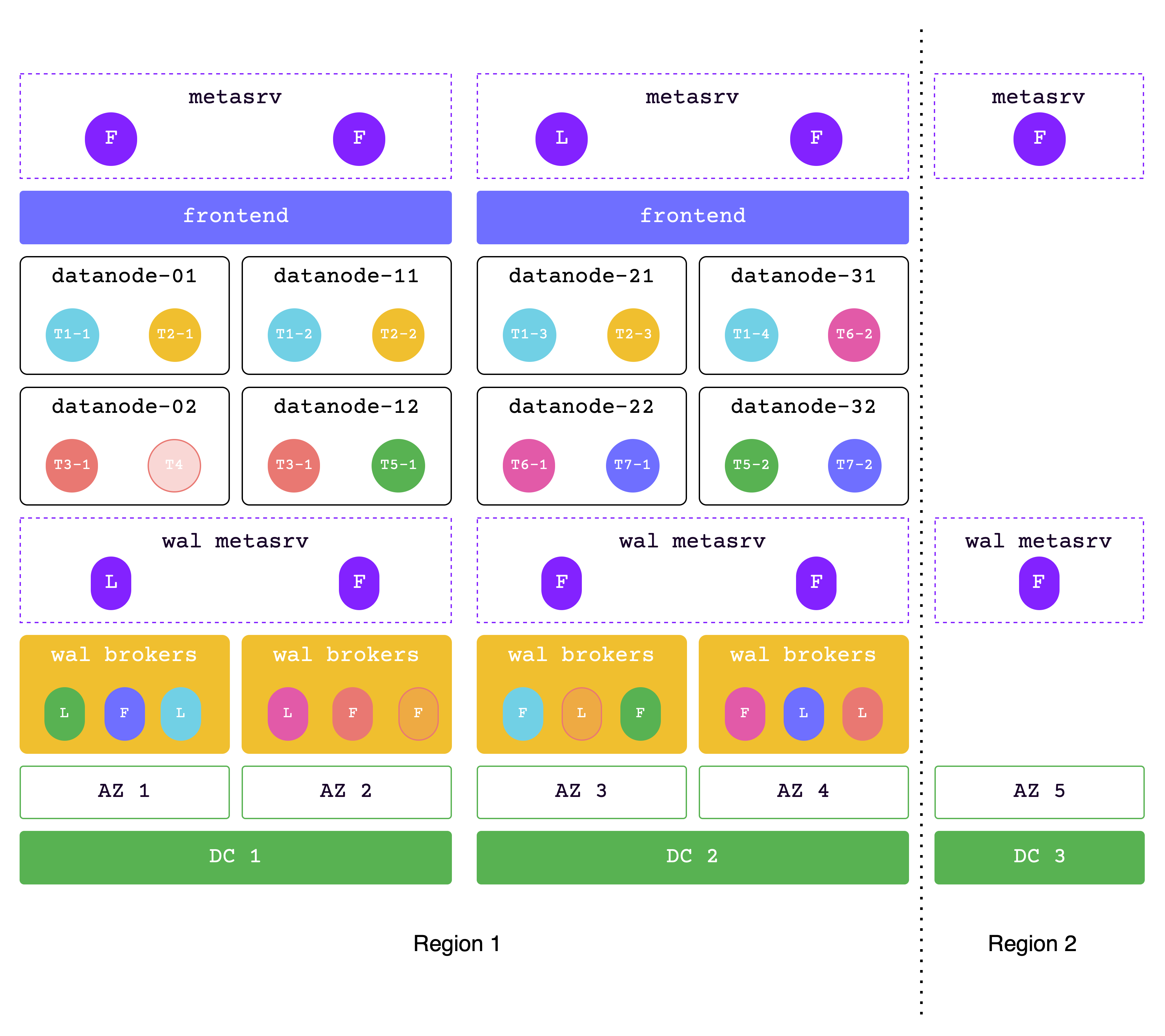
In this solution, the data is in one region (2 DCs), while the metadata across 2 regions.
DC1 and DC2 are used together to handle read and write services, while DC3 (located in region2) is a replica used to meet the majority protocol. This architecture is also called the "2-2-1" solution.
Both DC1 and DC2 must be able to handle all requests in extreme situations, so please ensure that sufficient resources are allocated.
Latencies:
- 2ms latency in the same region
- 30ms latency in two regions
Supports High Availability:
- A single AZ is unavailable with the same performance
- A single DC is unavailable with almost the same performance
If you want a regional-level disaster recovery solution, you can take it a step further by providing read and write services on DC3. So, the next solution is:
Data across 2 regions
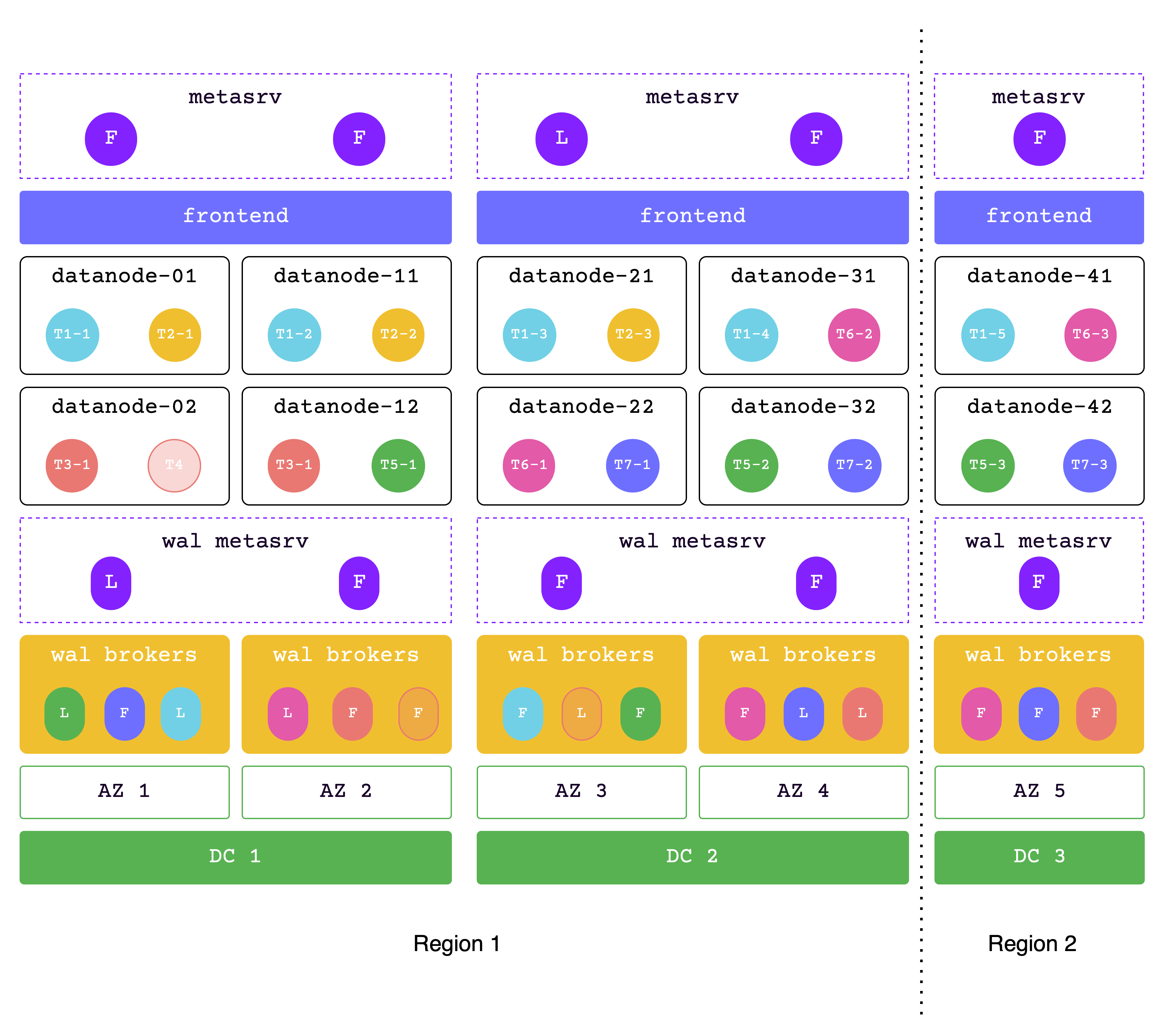
In this solution, the data across 2 regions.
Each DC must be able to handle all requests in extreme situations, so please ensure that sufficient resources are allocated.
Latencies:
- 2ms latency in the same region
- 30ms latency in two regions
Supports High Availability:
- A single AZ is unavailable with the same performance
- A single DC is unavailable with degraded performance
If you can't tolerate performance degradation from a single DC failure, consider upgrading to the five-DC and three-region solution.
Metadata across 3 regions, data across 2 regions
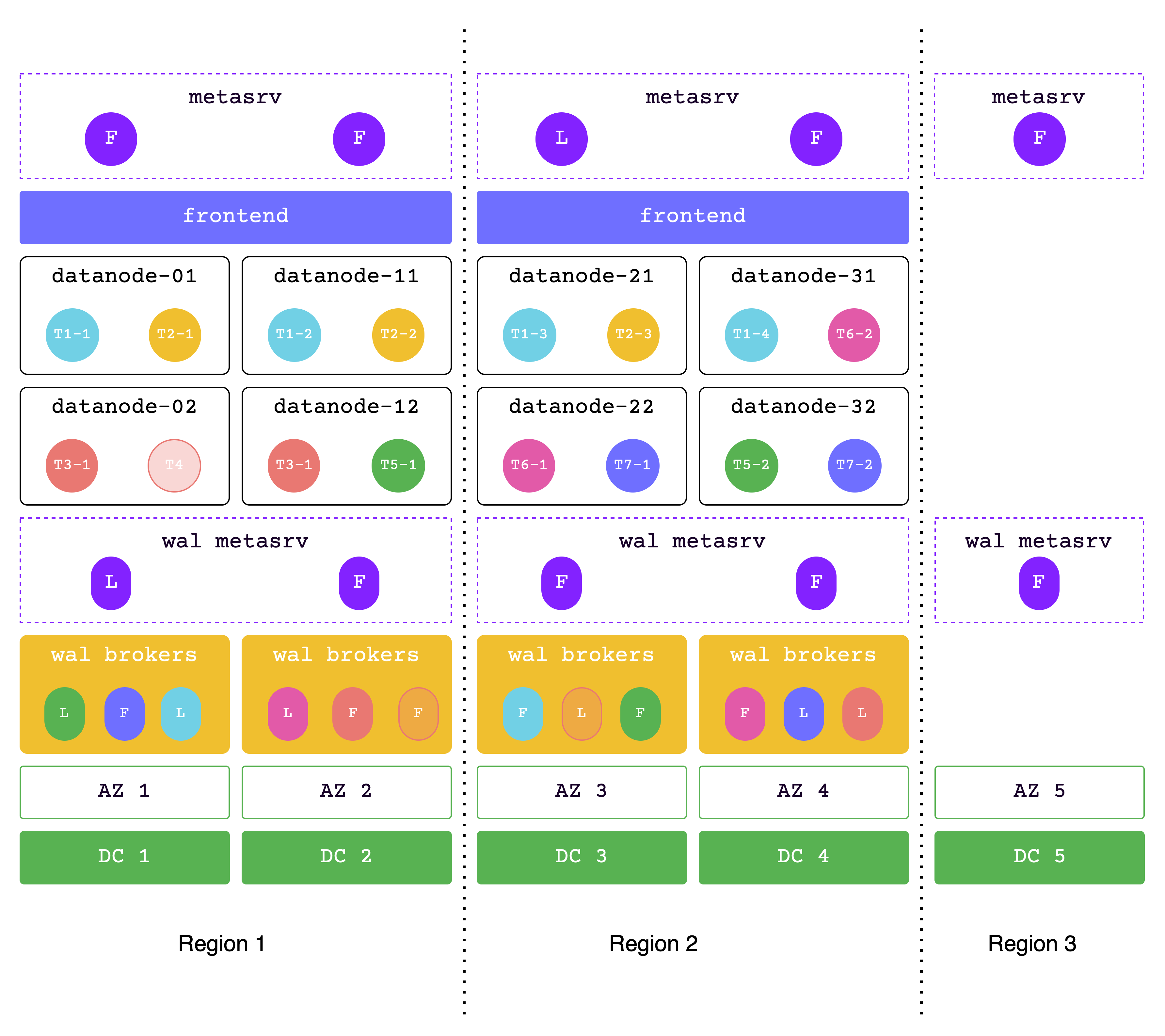
In this solution, the data across 2 regions, while the metadata across 3 regions.
Region1 and region2 are used together to handle read and write services, while region3 is a replica used to meet the majority protocol. This architecture is also called the "2-2-1" solution.
Each of the two adjacent regions must be able to handle all requests in extreme situations, so please ensure that sufficient resources are allocated.
Latencies:
- 2ms latency in the same region
- 7ms latency in two adjacent regions
- 30ms latency in two distant regions
Supports High Availability:
- A single AZ is unavailable with the same performance
- A single DC is unavailable with the same performance
- A single region(city) is unavailable with slightly degraded performance
You can take it a step further by providing read and write services on both 3 regions. So, the next solution is: (This solution may have higher latency, so if that's unacceptable, it's not recommended.)
Data across 3 regions
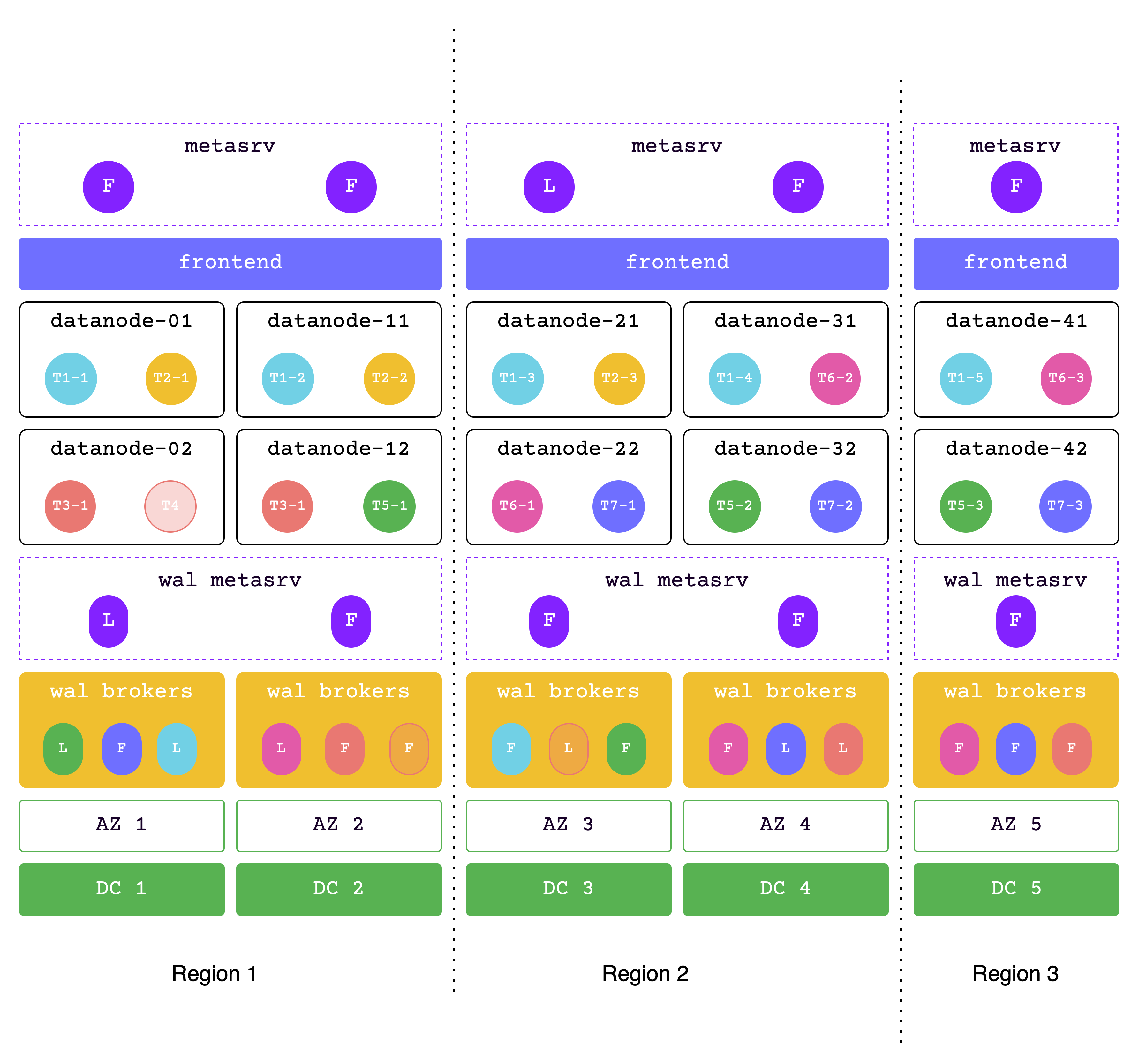
In this solution, the data across 3 regions.
In the event of a failure in one region, the other two regions must be able to handle all requests, so please ensure sufficient resources are allocated.
Latencies:
- 2ms latency in the same region
- 7ms latency in two adjacent regions
- 30ms latency in two distant regions
Supports High Availability:
- A single AZ is unavailable with the same performance
- A single DC is unavailable with the same performance
- A single region(city) is unavailable with degraded performance
Solution Comparison��
The goal of the above solutions is to meet the high requirements for availability and reliability in medium to large-scale scenarios. However, in specific implementations, the cost and effectiveness of each solution may vary. The table below compares each solution to help you choose the final plan based on your specific scenario, needs, and costs.
Here is the content formatted into a table:
| Solution | Latencies | High Availability |
|---|---|---|
| Metadata across 2 regions, data in the same region | - 2ms latency in the same region - 30ms latency in two regions | - A single AZ is unavailable with the same performance - A single DC is unavailable with almost the same performance |
| Data across 2 regions | - 2ms latency in the same region - 30ms latency in two regions | - A single AZ is unavailable with the same performance - A single DC is unavailable with degraded performance |
| Metadata across 3 regions, data across 2 regions | - 2ms latency in the same region - 7ms latency in two adjacent regions - 30ms latency in two distant regions | - A single AZ is unavailable with the same performance - A single DC is unavailable with the same performance - A single region(city) is unavailable with slightly degraded performance |
| Data across 3 regions | - 2ms latency in the same region - 7ms latency in two adjacent regions - 30ms latency in two distant regions | - A single AZ is unavailable with the same performance - A single DC is unavailable with the same performance - A single region(city) is unavailable with degraded performance |